Linguistic Technology of Semato -- Overview
The Semato software implements a morphological, syntactical and semantical analyzer of French and English. The linguistic analysis is carried out on all the phrases in your corpus, at the time of its indexation.
A spreadsheath file produced at the time of indexing will help us understand the language work done. This matrix presents all the words of the corpus's phrases, a word by line and several columns. Columns C to G contain the elements constructed by Semato's linguistic analyzer. We take the example of the corpus SOTUS (State of the Union Speeches - 42 speeches by U.S. presidents):
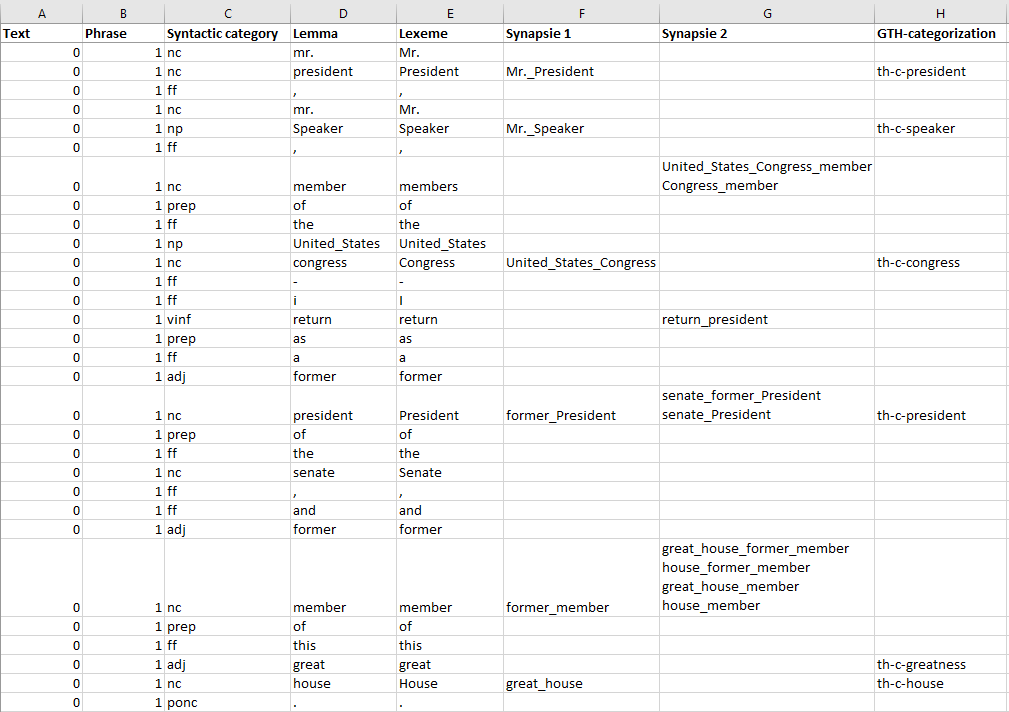
This matrix is extracted from the matrix-words-gth-c.xlsx (in its Excel version). This file is produced at the time of indexing and is deposited in the Semato-Ling folder. Below we will describe the different columns of this matrix.
Text and phrase
The excerpt presents first phrase (first phrase = 1 column B) of first text (the first text = 0, column A) in the SOTUS corpus. There are as many texts as there are paragraphs in these 42 speeches (5004 texts).
Syntactic category
The third column ( column C) shows the syntactic category of the word. The syntactic categories are:
- adj = adjective
- adv = adverb
- ff = functional form (articles, pronoms...)
- nc = noun - common
- np = noun - proper
- num = numeric
- ponc = punctuator
- prep = preposition
- vinf = verb - infinitive and conjugated
- vppa = verb - past participle
- vppe = verb - present participle
The paradigm of syntactic categories is strictly defined for the needs of the other two stages of morphosyntaxic analysis, lemmatization (column D) and the discovery of synapsies (columns F and G). This paradigm should not be sought for a stand-alone hypothesis about the possibilities and extensive functionality of syntactic categorization of the elements of a phrase. This is the bare minimum required to perform the other two morphosyntaxic steps of the analysis.
Lexeme and lemma
Lemmatization identify a canonical representative for a set of related word forms.
The column E shows the lexeme or input word of the analyzed text. This column is the one that most corresponds with the input text. The only changes are in terms of spaces and line breaks.
The column D gives the lemma of each lexeme. Lemmas are produced by the lemmatization procedure. Lemmatization yields a canonical form for each word to emphasize the semantic content of the word by abandoning the properties of time, number, mode, etc. Lemmatization is a kind of automatically giving a word the power to categorize the other words of its grammatical family. The lemma go, for example, refers to all the forms of this verb: go, goes, gone, going... The lemma car refers to the words: car, cars, car's, and cars'. Lemma is the infinitive for verbs and the singular for nouns. The other forms (adjectives adverbs, functional forms, etc.) are not lemmatized so there is no difference for them between lemma and lexeme (column D = column E).
The goal of lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. Lemmatization is not stemming. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma (Ref.: http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html).
Synapsies
The synapsies (presented to the columns F and columns G) identify textual segments that contain more than one word and allow to remove semantic ambiguities. The fundamental question of semantics is ambiguity. Words, taken out of context, often have more than one meaning, they are ambiguous. One can think of direct senses, but also of figurative senses. The word bat has two different direct meanings: a animal associated with vampires and a sports equipment used in baseball. Other words, such as the word health, for example, always have the same direct meaning (condition) but can be used in figurative senses: in the expressions health care or health insurance , we speak of the medical condition, and in the expression the economic health of the airline industry, we speak of a social condition.
To correctly manipulate the meaning of words, one must have access to their context. Without access to context, all manipulations can lead to errors. While the phrase can be considered to be a usually sufficient unambiguousness, it is also too long and complex to be an operational unit, its recurrence being almost null in the texts. To solve this problem, we have developed a technology in Semato called the screening of synapsies. Synapsies are the smallest contextual units to remove certain semantic ambiguities.
The list of synapsies quickly informs us of the content of a text, with little ambiguity. The idea is to be able to address the semantics of a corpus in a condensed way and with the greatest possible acuity.
To convince ourselves, let's compare the two lists below. The first list consists of all the lexemes found in the second list. This second list is constructed of all the synapsies containing lemma health in the SOTUS corpus. Read the first list and try to get an thematic idea of the text from which these words are extracted. Then redo the exercise with the second list.
First list : lexemes
Second list : synapsies
The screening of synapsies is based on a morphosyntaxic analysis of the phrase. It is therefore not a question of simply identifying repeated segments in the texts. The majority of synapsies in a text have only one occurrence and cannot be detected by a text segment counting approach. Recurrence can help to find terms (the objects of terminology, health care for example), but these are only a small subset of the synapsies present in a text. In the list above, 177 of the 220 synapsies appear only once in the SOTUS corpus.
The technique of repeated segments will also miss the numerous incise synapsies in complex nominal units and coordinations. Example, in the segment the brave men and women of our armed forces Semato will find 12 synapsies:
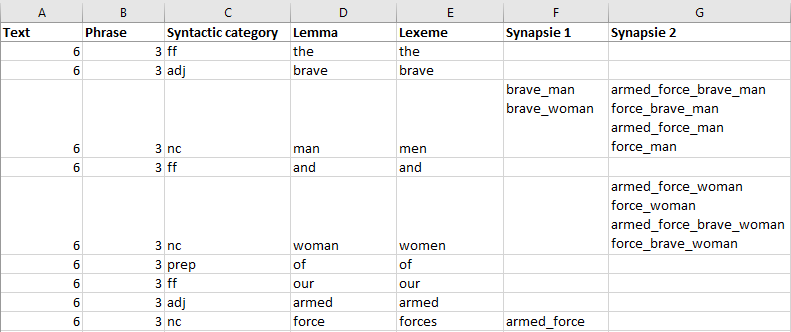
Only a system based on morphosyntaxic analysis rules can find these coordinated synapsies.
The algorithm constructs two lists of synapsies ( column F- synapsies 1 and column G - synapsies 2). The list synapsies 1 (column F) contains the units considered the most interesting. The synapsies list 2 (column G) contains other synapsies whose structure is less reliable. The second list (synapsies 2) contains prepositional expansions built on prepositions: with, for, without, on, of, etc. It also deposits constructions that contain infinitive expansions ( sewing machine) and segments whose head is verbal ( share_story. The sum of the two lists therefore provides the maximum coverage for those who want to be sure not to run out of synapsies. In addition, the use of the first list (synapsies 1) will ensure high quality for the purpose of screening for textual information. It should be noted in both lists that synapsies are presented in their lemmatized form, the spaces being replaced by underlines.
Synapsies present the syntagmatic contexts of a given word. A syntagmatic relationship is a concatenation relationship (words that follow each other); synapsies are syntagmas. The syntagmatic level quickly informs of the different meanings that a word can take, for a given corpus. We will now see that Semato's technology also manipulates another aspect of the semantics of words for a given corpus: the level of paradigmatic contexts.
Semantic fields
Before we describe the H column, we must present the semantic fields.
Semantic fields are defined at the language level. Semantic fields have been defined for the majority of lemmas of the language, plus a number of synapsies, those that can be considered as common terms of the language; for the rest of this description, synapsies being rare in the fields, we will speak only of lemmas.
The semantic field of a given lemma includes other lemmas who have, with the first, a relationship of semantic proximity.
Semato's semantic fields are built on two types of semantic proximity: morpho-etymological proximity and synonymic proximity.
In the memory of Semato, more than 130,000 semantic fields were collected for English and more than 150,000 for French. Here, for example, at the level of the English language, the semantic field of the lemma work:
- work (English level, 84 elements) : (artwork, bodywork, bookwork, brainworker, brickwork, bridgework, busywork, cabinetwork, casework, caseworker, clockwork, co-worker, deskwork, earthwork, fieldwork, glasswork, glassworker, groundwork, handiwork, housework, ironwork, lapwork, latticework, lifework, linkwork, meshwork, metalwork, metalworker, metalworking, millwork, needlework, nonworker, overwork, overworked, overworking, plasterwork, rackwork, reedwork, rework, rockwork, salework, shellwork, slopwork, stonework, stuccowork, taskwork, teamwork, underwork, underworker, waterwork, waxwork, waxworker, wickerwork, wirework, wonderwork, woodwork, woodworker, woodworking, workable, workbag, workbench, workbox, workday, worked, worker, workfellow, work, workforce, workful, working, workless, workload, workmaster, workplace, workshop, workspace, workstation, worktable, workways, workwoman, workyday, employment, oeuvre, working)
The semantic field of work contains 84 elements. These 84 elements are lemmas or synapsies that have their own semantic field; each of these fields in turn contains the lemma work. All defined semantic relationships are therefore bidirectional or, can we say, reciprocal.
In this approach, to give the meaning of a lemma is to show other lemmas. It is an extensional approach. A lemma is defined by a set of other lemmas, its semantic extension in the language, and it itself serves to define, in a similar way, other lemmas.
An intentional approach would instead involve atoms of meaning outside the language (for example, a lemma would be defined as a set of semes: eat = action + food + survival etc.).
The semantic field of a lemma in a corpus is a subset of the semantic field it has in the language. Here is the semantic field of lemma work in the SOTUS corpus.
- work (SOTUS corpus, 10 elements) : (employment, overworked, teamwork, work, workable, worker, workforce, working, workplace, workshop)
At the language level, all semantic fields are different. There are no two identical fields among the 130,000 fields defined for English. The fields are not identical, but they are not sealed; it is understood that two fields can have an intersection. For example, at the level of the English language, the two fields work and worker have 14 lemmas in common:
- work (84 elements, English level): (artwork, bodywork, bookwork, brainworker, brickwork, bridgework, busywork, cabinetwork, casework, caseworker, clockwork, co-worker, deskwork, earthwork, employment, fieldwork, glasswork, glassworker, groundwork, handiwork, housework, ironwork, lapwork, latticework, lifework, linkwork, meshwork, metalwork, metalworker, metalworking, millwork, needlework, nonworker, oeuvre, overwork, overworked, overworking, plasterwork, rackwork, reedwork, rework, rockwork, salework, shellwork, slopwork, stonework, stuccowork, taskwork, teamwork, underwork, underworker, waterwork, waxwork, waxworker, wickerwork, wirework, wonderwork, woodwork, woodworker, woodworking, work, workable, workbag, workbench, workbox, workday, worked, worker, workfellow, workforce, workful, working, workless, workload, workmaster, workplace, workshop, workspace, workstation, worktable, workways, workwoman, workyday)
- worker (18 elements, English level): (brainworker, caseworker, co-worker, garmentworker, glassworker, metalworker, nonworker, prole, proletarian, steelwork, steelworker, work, workable, worked, worker, workful, working, workways)
- intersection (14 elements, English level): (brainworker, caseworker, co-worker, glassworker, metalworker, nonworker, work, workable, worked, worker, workful, working, workways)
Let's compare the intersections of two semantic fields between the English level and the level of SOTUS corpus.
- work (10 elements, SOTUS level): (employment, overworked, teamwork, work, workable, worker, workforce, working, workplace, workshop)
- worker (5 elements, SOTUS level): (steelworker, work, workable, worker, working)
- intersection (4 elements, SOTUS level): (work, workable, worker, working)
At the corpus level, with less semantic variability than for the language as a whole, intersections will be proportionately greater.
We try to measure the relative importance of the intersection between two semantic fields. At the language level, we have an intersection of 14 elements with the 84 elements of work and the 18 elements for worker. As a percentage, we will have these intersection values:
- Level of language:
- 14/84 - 16.67% for work
- 14/18 - 77.78% for worker
and therefore an average of 8.72% for these two fields at the level of English.
- Level of the SOTUS corpus:
- 4/10 - 40% for work
- 4/5 - 80% for worker
and therefore an average of 60% for these two fields in the SOTUS corpus.
The increase in the average intersection at the corpus level intuitively shows us the interest in merging certain fields for a given corpus.
The more semantically homogeneous the corpus, the more condensation it exerts on the fields, increasing their intersections. As much as, at the level of language, all the effort (in the design of Semato) was to isolate specific fields (there are no two identical fields at the level of the language), as much, at the level of the corpus, will we look for mechanisms to merge the fields and thus allow the emergence of more inclusive sets that are good candidates for the categorization/annotation of texts.
We will see in the next section, how semantic condensation will allow us to migrate, through this fusion mechanism, from semantic fields to the construction of themes.
Themes
The themes are the last level of Semato's linguistic description. The themes are presented at the H column of the matrix. The mechanism of the construction of the themes is called GTH (Generation of THemes). Semato proposes two types of themes: the GTH-O (O for Open), and the GTH-C (C for Concise) built mainly on a constraint called sealing. Sealing is a property associated to a theme list. The themes of a sealed list have ingredients that are specific to them. The same ingredient cannot be found in two themes of a sealed list of themes (we'll come back to that).
The themes are composed of lemmas and synapsies. These lemmas and synapsies are the ingredients of the theme. A theme has a name and a frequency. The name of a theme always starts with characters th-c- for GTH-C themes, or th-o- for those of the GTH-O. The frequency gives the number of phrases in the corpus where any of the ingredients of the theme appears. Example of some themes of the GTH-C on SOTUS corpus:
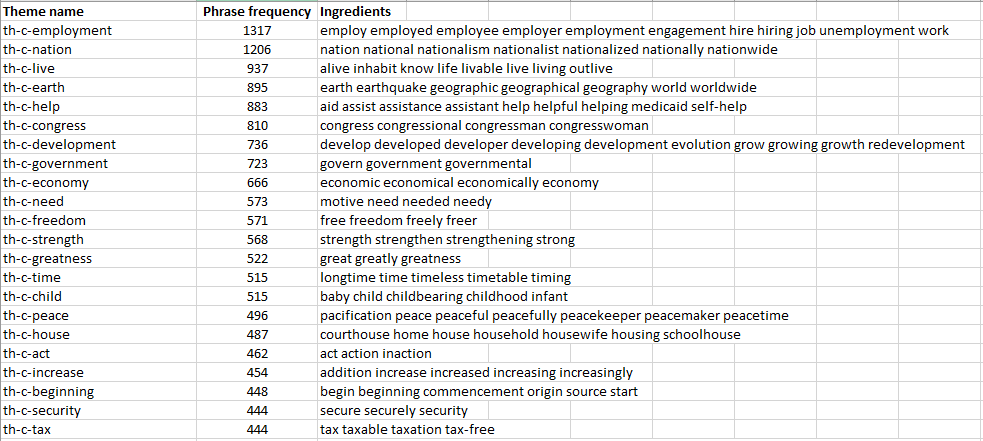
The ingredients of the themes are given in two files produced by Semato:
The themes are sort of super semantic fields. They are mainly built by a fusion mechanism between fields. This mechanism is the same for GTH-O and GTH-C, the difference being based on a single additional rule that will ensure the sealing of the themes of the GTH-C.
Fusion will not affect all semantic fields in the corpus. Unmerged fields will become autonomous themes. The fusion procedure having, in their case, the merit of declaring them semantically specific for this corpus.
The themes found by Semato are certainly not the only elements that are good candidates for a relevant semantic description. Semato gives you all the raw material (lemmas, synapsies and semantic fields) to write other algorithms.
All that follows now, explains in more detail the fusion mechanism at work in the two GTH.
The fusion of the fields takes several steps. Both GTH follow the same steps plus one (last one) that implements the sealing rule for GTH-C. Here are these steps.
- The lexicon of the lemmas and synapsies of the corpus is examined in order to construct a list of semantic fields candidates for fusion. The semantic field of each lemma/synapsie, whose frequency is equal to or greater than a value calculated according to the volume of the corpus, will be retained. The principle being that the higher the volume of the corpus, the higher the frequency of the lemma/synapsie retained will have to be as well. In our example corpus (SOTUS), this value is calculated equal to 4. Therefore, we retain all lemmas and synapsies whose frequency is equal to or greater than 4 in the corpus, in order to examine their semantic field.
- Each lemma/synapsie retained receives its semantic field. Such a field has the shape of a list, each element of which is itself a list containing a lemma/synapsie accompanied by its frequency. Thus, always in our SOTUS corpus, the lemma "work" relates the following semantic field:
- (("work" 715) ("employment" 71) ("workforce" 2) ("workshop" 1) ("overworked" 1) ("teamwork" 3) ("workable" 5) ("worker" 151) ("workplace" 16) ("working" 52))
The lemma/synapsie at the origin of the field is called the head of the field. The head of the field, here ("work" 715), is always placed at the beginning of the field.
For the SOTUS corpus, the procedure selected 3196 fields.
- This list contains doublets, triplets, etc. At the language level, it is impossible, by definition, for two lemmas to have the same field. At the corpus level, it is possible, and all the more frequent since the volume of the corpus is small. In the SOTUS corpus, 1796 fields will have been removed from the list. There will be some left in 1400. Doublets or triplets are therefore identical lists except for the order of the items. Example of doublets:
- (("legislature" 1) ("legislation" 151) ("legislate" 4) ("legislative" 31) ("legislatively" 1) ("legislator" 2))
- (("legislation" 151) ("legislate" 4) ("legislative" 31) ("legislatively" 1) ("legislator" 2) ("legislature" 1))
Only one semantic field will be retained per doublet or triplet, etc.
- Each semantic field receives a weight called SFW (Semantic Field Weight). This weight is the sum of the frequencies of each of its elements, multiplied by the number of items on the list. Thus, the weight of the SFW field presented above ("work") is 1017 * 10 = 10170. There are 10 items with a frequency sum of 1017. This formula of the SFW takes into account both the frequency importance of the field to the corpus as well as its semantic richness/diversity (the number of different elements in the field). The list of all selected semantic fields (called Semantic Fields List SFL) is then ordered according to their weight (SFW), with the heaviest fields placed at the top of the list.
Here are some of the first items of this list of 1400 fields for the SOTUS corpus; each field is preceded by its SFW:
- 14487 (("employment" 71) ("employee" 27) ("employ" 5) ("employed" 1) ("employer" 18) ("unemployment" 77) ("engagement" 1) ("hire" 19) ("hiring" 3) ("job" 380) ("work" 715))
- 10170 (("work" 715) ("employment" 71) ("workforce" 2) ("workshop" 1) ("overworked" 1) ("teamwork" 3) ("workable" 5) ("worker" 151) ("workplace" 16) ("working" 52))
- 8442 (("nation" 867) ("national" 324) ("nationalism" 3) ("nationalist" 1) ("nationalized" 2) ("nationally" 3) ("nationwide" 6))
- 8056 (("american" 1119) ("african-american" 1) ("America" 893) ("un-american" 1))
- 6936 (("help" 640) ("aid" 71) ("assist" 39) ("assistance" 99) ("helping" 7) ("assistant" 4) ("helpful" 2) ("self-help" 5))
- 5900 (("life" 346) ("biological" 16) ("biomass" 1) ("biotechnology" 1) ("lifeline" 1) ("lifetime" 20) ("livable" 6) ("live" 163) ("living" 28) ("wildlife" 8))
- 5697 (("development" 181) ("developing" 31) ("develop" 127) ("developed" 3) ("developer" 1) ("redevelopment" 1) ("evolution" 5) ("growing" 58) ("growth" 226))
- 5262 (("earth" 56) ("geographic" 1) ("geographical" 1) ("geography" 1) ("earthquake" 2) ("world" 816))
- 5232 (("aid" 71) ("medicaid" 16) ("assist" 39) ("assistance" 99) ("help" 640) ("helping" 7))
- 5213 (("pay" 182) ("paycheck" 17) ("overpayment" 1) ("paid" 1) ("payable" 1) ("repay" 5) ("repayment" 1) ("taxpayer" 58) ("payroll" 10) ("salary" 7) ("wage" 69) ("paying" 2) ("payment" 47))
- Several fields have intersections, semantic fields are not sealed between them. The main objective of the GTH is to merge fields with significant intersections. The essence of the algorithm is therefore to calculate this significance. All fields will be compared two by two. The list of semantic fields (SFL) will always remain in the descending order of the SFW (Semantic Field Weight). Therefore, a heavier field (FA) will always be compared to an equal or less heavy field (FB). Each field will be compared successively to all other fields. Let's set the terms:
- SFL: list of all semantic fields selected for the GTH;
- SFW: weight of a semantic field;
- FA: heaviest field of the two fields compared;
- FB: the least heavy (or equal) field of the two fields compared (SFW-FA >= SFW-FB);
- INTER: intersection between FA and FB fields;
- SFW-FA: SFW of FA;
- SFW-FB: SFW of FB;
- SFW-INTER: SFW of the intersection between FA and FB;
- %INTER-FA: percentage of SFW-INTER on SFW-FA;
- %INTER-FB: percentage of SFW-INTER on SFW-FB;
- %AVERAGE: average of %INTER-FA and %INTER-FB;
- %FUSION: percentage that needs to be matched or beaten for a fusion. This percentage is calculated for the corpus. For the SOTUS corpus, it was calculated at 40%. The larger the corpus, the higher it is. To the limit, if the corpus were equal to the entire language, it would have 100% value and no merger would be allowed.
- Fields are compared one by one. The first field will be compared in turn with each of the other fields. In this comparison, we will have two FA and FB variables that will feed on the SFL. Imagine a simple formal example:
- SFL = (f1 f2 f3 f4), our list contains 4 fields.
- First round, FA has f1 content (noted: FA(f1)). Fa(f1) is compared to each of the remaining elements of the SFL (f2 f3 f4). So we'll have three comparisons:
- FA(f1) with FB(f2),
- FA(f1) with FB(f3) and
- FA(f1) with FB(f4)
- Second round, f1 is removed and FA(f2) is compared to each of the remaining elements of the SFL (f3 f4). So we'll have two comparisons:
- FA(f2) with FB(f3) and
- FA(f2) with FB(f4)
- Third round, f2 is removed and FA(f3) is compared to each of the remaining elements of the SFL (f4). So we'll have one last comparison:
- The fusion rule. Let's look at the comparison of two semantic fields, those of the "pay" and "taxpayer" lemmas in our SOTUS corpus. The field of "pay" has a SFW of 5213 (will become FA) while that of the lemma "taxpayer" has a SFW of 2028 (will become FB).
- FA: (("pay" 182) ("paycheck" 17) ("overpayment" 1) ("paid" 1) ("payable" 1) ("repay" 5) ("repayment" 1) ("taxpayer" 58) ("payroll" 10) ("salary" 7) ("wage" 69) ("paying" 2) ("payment" 47))
- SFW-FA: 401 * 13 = 5213
- FB: (("taxpayer" 58) ("pay" 182) ("tax" 436))
- SFW-FB: 676 * 3 = 2028
- INTER: (("pay" 182) ("taxpayer" 58))
- SFW-INTER: 240 * 2 = 480
- %INTER-FA: 480/5213 = 9.21%
- %INTER-FB: 480/2028 = 23.67%
- %AVERAGE: (9.21% + 23.67%) / 2 = 16.44%
- Verdict: rejected fusion
The intersection is 2 elements (("pay" 182) ("taxpayer" 58)). To measure the relative importance of this intersection, its SFW-INTER (480) is reported to the SFW-FA (5213) and to the SFW-FB (2028), and then we calculate the average of the two percentages obtained. We get 16.44% here. Subsequently, this percentage of the intersection of the two fields is compared to the percentage of fusion (%FUSION) required for fusion.
If the percentage average observed between the two lists is greater than or equal to the %FUSION variable calculated on the basis of corpus volume, the fusion takes place. In our example, the volume of the corpus requires an average of 40% or more. On this basis of the comparisons of the SFW between the two fields, the fusion is therefore rejected since 16.44% is less than 40%.
Less formally, this means that the algorithm refuses to integrate the lemma "tax" into a possible "pay" theme. The lemma "tax" will eventually build its own theme.
In the next example, the fusion will be accepted:
- FA: (("help" 640) ("aid" 71) ("assist" 39) ("assistance" 99) ("helping" 7) ("assistant" 4)
("helpful" 2) ("self-help" 5))
- SFW-FA: 867 * 8 = 6936
- FB: (("aid" 71) ("medicaid" 16) ("assist" 39) ("assistance" 99) ("help" 640) ("helping" 7))
- SFW-FB: 872 * 6 = 5232
- INTER: (("helping" 7) ("help" 640) ("assistance" 99) ("assist" 39) ("aid" 71))
- SFW-INTER: 856 * 5 = 4280
- %INTER-FA: 4280/6936 = 81.80%
- %INTER-FB: 4280/5232 = 61.71%
- %AVERAGE: (81.80% + 61.71%) / 2 = 71.76%
- Verdict: accepted fusion
- If there is no fusion, the FA is compared with the semantic field that follows the FB in the SFL; this field becomes the new FB.
If there is a fusion, the fusioned FA-FB list becomes the new FA for further comparisons of the current round. The new FA resulting from the fusion is compared to the FB that follows the fusioned FB. The fusioned FB is removed from the SFL.
- At the end of the first round, the FA becomes a theme of the GTH, whether it has fusioned or not. The name of the theme is the head of the FA to which "th-o" or "th-c" is added according to the current GTH. The FA becomes a theme on the condition that its total frequency (including fusions) is equal to or greater than a variable set by a calculation of the volume of the corpus. The FA is removed from the SFL and therefore from any subsequent comparison.
The second round therefore begins with an FA fed by the first FB not withdrawn by fusion.
In our SOTUS corpus, the GTH-O will have built 873 themes, 149 of which by fusion. The GTH-C will have built 836 themes, 109 of which by fusion.
- The sealing rule. The GTH may be sealed or not sealed. Only the GTH-C is sealed. In a non-sealed GTH, different themes may have identical ingredients. The GTH-O of the SOTUS corpus builds 3 different themes containing the ingredient lifetime:
| th-o-time
| 535
| lifetime, longtime, time, timeless, timetable, timing
|
| th-o-life
| 590
| biological, biomass, biotechnology, life, lifeline, lifetime, livable, live, living, wildlife
|
| th-o-lifetime
| 873
| life, lifetime, time
|
In GTH-C, only one theme will contain the ingredient lifetime. The th-c-biological theme recovers the ingredient lifetime, thus removed from the other themes:
| th-c-biological
| 47
| biological, biomass, biotechnology, lifeline, lifetime, wildlife
|
| th-c-time
| 515
| longtime, time, timeless, timetable, timing
|
The sealing rule is simple: as soon as a theme is formed (at the end of a turn), all its ingredients are removed from all fields still to be examined. In this comparison, lemmas and synapsies are considered to be stand-alone ingredients in the composition of themes. The family_lifetime ingredient is not considered an instance of the family ingredient or an instance of the ingredient lifetime.
Synapsies in GTH
Themes from both GHTs (objects and categorization) may contain synapsies. First, a synapsie may have a semantic field. Synapsie cutting_out, for example, has the semantic field: (ablation, extirpation, excision).
Second, a synapsie can yield other synapsies following an examination of the semantic fields of its constituents. We will look for synapsies with semantic fields close to each other. The algorithm breaks down a synapsie into its constituents and examines their semantic fields. The GTH examines one by one all the synapsies found in the corpus. Examination of significant_progress synapsie for example, will yield the two semantic fields below, for the lemmas significant and progress:
- significant : (significant, important, substantial)
- progress : (progress, advance, advancement, progression)
The algorithm will combine two by two all the elements of the two sets: the semantic field of significant will be combined with each of the 4 elements of the semantic field of progress (significant_progress, significant_advance, significant_advancement, significant_progression). Then it will be the turn of important to be combined with the elements of the field progress, and after, the turn of substantial. A list of 12 pairs (3*4) will be built. These couples will be remembered for those that are performed in synapsies of the corpus. All these synapsies of the corpus where an element of the semantic field of significant with an element of the semantic field of progress are brought together into a new theme th-c-significant_progress. We will have found 4 synapsies showing a semantic proximity with significant_progress into the SOTUS corpus.
| th-c-significant_progress
| 11
| important_progress, significant_advance, significant_progress, substantial_progress
|
Here is an other example in SOTUS:
| th-c-pay_increase
| 8
| pay_increase, salary_increase, wage_increase
|
|